Ausfallzeiten von IT-Services - Downtime
Downtime - Mean Time To Repair (MTTR)
Mit der Ausfallzeit (Downtime), ist die Zeit gemeint, während der ein IT-Service, ein IT-System oder IT-Netzwerk für den Benutzer zu den definierten Betriebszeiten nicht zur Verfügung steht.
Der Grund für den Ausfall kann ein Fehler in der Hardware oder Software sein, der die Downtime verursacht hat, es kann sich aber auch um Bedienfehler handeln oder um eine bewusste, vorsätzliche Ausfallzeit, beispielsweise um Wartungs- und Reparaturarbeiten durchführen oder Software-Updates oder neue Anwendungssoftware laden zu können.
- Im Fehlerfall handelt es sich um eine ungeplante Downtime.
- Im Wartungsfall um eine geplante Downtime.
Die Klassifizierung der Verfügbarkeit bestimmt die Länge der Ausfallzeit. Diese kann bei einfacher Verfügbarkeit von 99,50 % bei 48 Stunden pro Jahr liegen und bei Non-Stopp-Verfügbarkeit bei 99,999%. (< 6 Minuten)
Die Verfügbarkeit wird bestimmt durch die Faktoren Mean Time Between Failures (MTBF), das ist die mittlere Zeitspanne zwischen dem Auftreten von zwei Fehlern, und Mean Time To Repair (MTTR), das ist die Dauer der Störungsbeseitigung. Eine hohe Verfügbarkeit resultiert aus einer möglichst großen MTBF und einer möglichst kleinen MTTR.
Kennzahlen-Steckbrief
Kennzahlen-Stammdaten
| Kennzahlen-Titel | IT-Downtime (je IT-Service) |
|---|---|
| Kennzahlen-ID | IT-PPI.downtime |
| Kennzahlen-Typ | Qualität-Kennzahlen |
| Kennzahlen-Beschreibung | Downtime bezieht sich normalerweise auf die Zeit, in der ein IT-Service, ein IT-System oder eine Prozesse bzw. Dienstleistung nicht verfügbar ist oder nicht ordnungsgemäß funktioniert. Während der Downtime können Benutzer nicht auf die Dienste oder Ressourcen zugreifen, was zu Produktivitätsverlusten, Unterbrechungen des Geschäftsbetriebs oder anderen Beeinträchtigungen führen kann. |
| Interpretation | Eine geringere Downtime zeigt an, dass der IT-Service oder IT-Prozess eine hohe Verfügbarkeit (Availability) und Zuverlässig (Reliability) hat. Geplante vs. ungeplante Ausfälle: In der Regel werden nur ungeplante Ausfälle bei der Berechnung der Verfügbarkeit berücksichtigt. Geplante Wartungsarbeiten werden oft ausgeschlossen. |
| Messverfahren | Automatische Überwachung: Monitoring-Systeme erfassen Ausfallzeiten automatisch durch die Überwachung von Systemen und Anwendungen (Ping, Agent). Syslog Daten: Syslog Daten können verwendet werden um Ausfälle zu protokollieren. Manuelle Aufzeichnungen: In einigen Fällen können Ausfallzeiten manuell durch IT-Personal protokolliert werden. |
| Messdaten | Verfügbarkeitsmessung mittel pings in Messtabellen, Log-Einträge. |
| Berechnungsmethode | Verfügbarkeit = (Gesamtzeit - Ausfallzeit) / Gesamtzeit. In diesem Zusammenhang ist die Gesamtzeit bzw. Uptime die vereinbarte Betriebszeit.  Beispiel: Angenommen, ein IT-Service sollte im Laufe eines Monats (720 Stunden) verfügbar sein.Wenn der Service insgesamt 7,2 Stunden ausgefallen ist, beträgt die Verfügbarkeit: (720 - 7,2) / 720 = 0,99 *100 = 99% |
| Maßeinheit [...] | Up or Down in der definierten Zeitspanne [0 oder 1 ] |
| Adressat | Prozess-Stakeholder IT-Service-Owner |
| Gültigkeit | gemäß Vorgaben aus der Dokumentenlenkung zur Aufbewahrungsfristen. |
| Links | - |
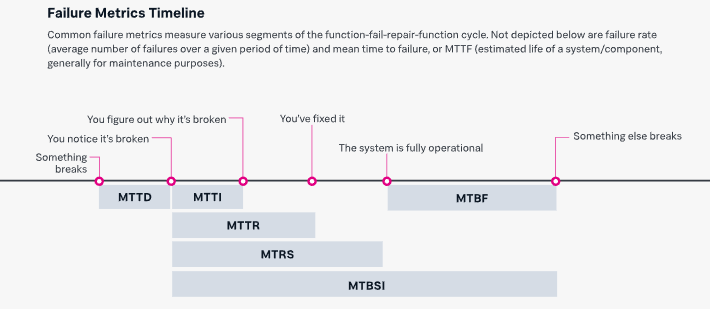
Typische Ausfallmetriken wie MTTR, MTBF, MTTF
Zu den gängigen Ausfallmetriken gehören:
- Mean-Time-To-Repair (MTTR): Die durchschnittlich für die Reparatur und Wiederherstellung eines ausgefallenen Systems benötigte Zeit. Bei Mean Time To Repair handelt sich um eine Messgröße für die Wartbarkeit von reparierbaren Komponenten oder Services. Je nach Komplexität des Geräts und des zugehörigen Problems kann die MTTR in Minuten, Stunden oder Tagen gemessen werden. Die Abkürzung der MTTR kann dabei auch für Mean-Time-To-Recovery, Mean-Time-To-Resolve oder Mean-Time-To-Resolution stehen.
- Mean-Time-Between-Failure (MTTF): Die durchschnittliche Betriebsdauer zwischen einem Geräteausfall oder Systemabsturz und dem nächsten. In Unternehmen wird die MTBF herangezogen, um die Zuverlässigkeit und Verfügbarkeit von Systemen und Komponenten vorherzusagen. Diese Kennzahl wird durch Nachverfolgung der Zeitspanne zwischen System-/Komponentenausfällen während des normalen Betriebs berechnet.
- Mean-Time-To-Failure (MTTF): Die durchschnittliche Betriebsdauer eines Geräts oder Systems bis zum Ausfall. In der Regel erfassen IT-Teams die entsprechenden Daten, indem sie Systemkomponenten über mehrere Tage oder Wochen beobachten. Diese Kennzahl ähnelt zwar der MTBF, wird jedoch normalerweise verwendet, um Elemente zu beschreiben, die ausgetauscht werden müssen, z. B. ein Bandlaufwerk in einem Backup-Array, während die MTBF für Elemente verwendet wird, die entweder repariert oder ersetzt werden können.
- Mean-Time-To-Detect (MTTD): Die durchschnittliche Zeitspanne zwischen dem Eintreten eines Problems und dessen Erkennung. Die MTTD bezeichnet die Zeit, die vergeht, bevor die IT-Abteilung ein Service-Ticket erhält und die Stoppuhr für die MTTR startet.
- Mean-Time-To-Investigate (MTTI): Die durchschnittliche Zeitdauer zwischen der Erkennung eines IT-Incidents und dem Beginn der Untersuchung seiner Ursache mit Blick auf die Lösungsfindung. Mit anderen Worten, die Zeitspanne zwischen MTTD und dem Beginn der MTTR.
- Mean-Time-To-Restore-Service (MTRS): Die durchschnittliche Zeitspanne von der Erkennung eines Incidents bis zur erneuten Bereitstellung des betreffenden Systems oder der Komponente für die Benutzer. Die MTRS unterscheidet sich folgendermaßen von der MTTR: Während die MTTR angibt, wie lange es dauert, ein Element zu reparieren, bezieht sich die MTRS darauf, wie lange es dauert, den Service wiederherzustellen, nachdem das Element repariert wurde.
- Mean-Time-Between-System-Incidents (MTBSI): Die durchschnittliche Zeitspanne zwischen der Erkennung zweier aufeinanderfolgender Incidents. Die MTBSI wird durch Addition von MTBF und MTRS berechnet (MTBSI = MTBF + MTRS).
- Ausfallrate (Failure Rate): Eine weitere Metrik für die Zuverlässigkeit, mit der die Häufigkeit des Ausfalls einer Komponente oder eines Systems gemessen wird. Die Ausfallrate wird als Anzahl der Ausfälle pro Zeiteinheit angegeben.
Kennzahlen-Werte
| Kennzahlen-Werte | |
|---|---|
| angestrebte Zielwert | Im jeweiligen SLA vereinbart. |
| Toleranzbereich | - |
| Eskalationsregel | Im jeweiligen SLA vereinbart. |
| Maßnahmen bei Grenzwertüberschreitung | - |
| Messzeitpunkte/-intervalle | 5 bis 15min Taktung |
| Betrachtungszeitraum | Jahr-Quartal-Monat |
| Operationalisierung | im IT-Monitoring-System (Prometheus, Grafana) |
| Messverantwortlicher | Prozessmanager, Servicemanager |
Kennzahlen-Darstellung
| Kennzahlendarstellung | |
|---|---|
| Kennzahlenvisualisierung | Kalender mit Tagesansicht und 24h Kacheln.  |
| Aggregationsstufe | Jahr-Quartal-Monate. |
| Kennzahlen–Berichterstatter | Prozessmanager, Servicemanager |
| Kennzahlen–Berichtsablage | Online-Auswertungen im Monitoring-System Auswertungen im Process-HUB, Service-HUB |